One-to-one targeting with affinity-based personalization
Affinity modeling as we know it is simple and effective, but product metadata can be better leveraged to predict the most relevant experience to users.

![]() Summarize this articleHere’s what you need to know:
Summarize this articleHere’s what you need to know:
- One-to-one targeting with affinity-based personalization uses product metadata to predict what a user is most likely to respond to, increasing engagement and conversion rates.
- Affinity modeling is based on the idea that the more a user interacts with a particular product or feature, the more likely they are to be interested in similar ones in the future, making product recommendations more relevant and effective.
- Affinity scores are calculated by considering the type of interaction (view, add to cart, purchase) and its recency, allowing for nuanced personalization based on a user’s specific actions.
- Affinity scores can be used to personalize the user experience in various ways, including recommending products, showing different content, and tailoring offers, leading to a more satisfying customer journey.
- The future of affinity-based personalization lies in leveraging machine learning to create even more sophisticated models that incorporate a wider range of factors, like site type, product variety, and time of day, for even more effective and dynamic personalization.
As marketers, our job is to analyze the behaviors of visitors as well as the products they interact with to gain a better understanding of how everything is connected. With this information, we can then build experiences that will truly resonate on an individual level.
However, despite our best efforts, as visitors become exposed to a wider range of brands, colors, styles, prices, and more, it gets harder to assign meaning to particular interactions. And oftentimes, the true nature of an engagement ends up lost in a web of complex data.
Replaced by a guessing game in which different combinations of targeting conditions are tested in hopes of matching the right experience to the right audience, this challenge is the reason affinity profiling came to be. Adding a score to a user based on the metadata connected to a product they’ve interacted with meant teams could better predict the most relevant items to them in the future.
But even in all of its glory, the industry is still naive in its application and implementation. In this post, I’ll explain where affinity is today and touch on the enormous untapped potential.
Calculating affinity
User affinity profiling starts by capturing each engagement with a digital property and then collecting all of the product attribute values associated with the interaction.
Quick Reference: Example User Affinity Signals | |
Engagement type: – Tthe interaction the user has with the product | Product attribute values: – Tthe characteristics describing the product |
| Product view Add to cart Purchase Filter product grid Add to wishlist Custom interaction | Color: red Gender: men Style: T Category: running |
For example, let’s take a look at a sample journey:
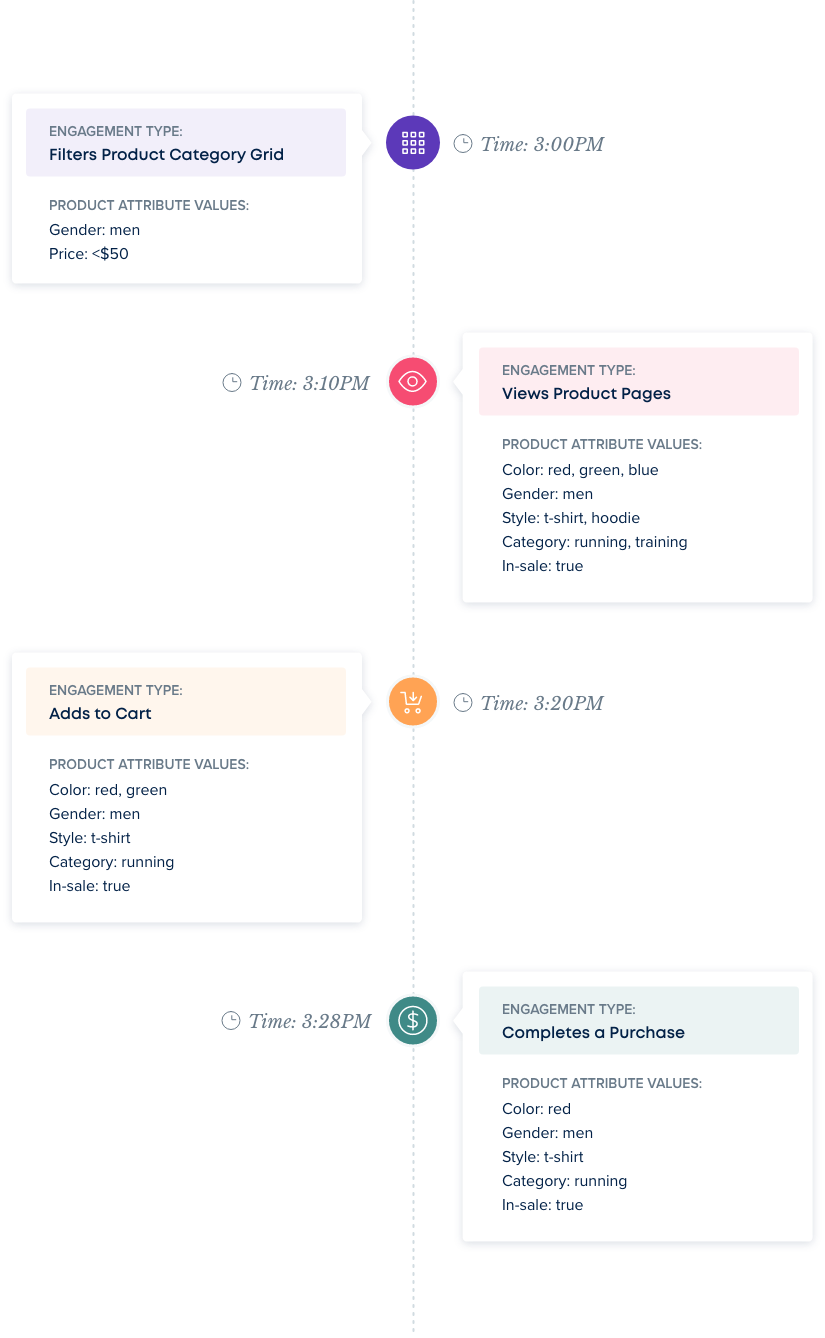
In the context of a single visitor, we might see four pageviews generated in which the product color was green, six in which the product was red, and two blue. Additionally, all of the items viewed consisted of Men’s t-shirt under $50. The visitor then places two items in their cart, a red and a green t-shirt, but ultimately purchases the red one.
| Attribute | Color | Style | Gender | Price Range | ||||||||
| Value: | Green | Red | Blue | T | Tank | Cami | Men | Women | Boys | Girls | <$50 | >$50 |
| Product view | 4 | 6 | 2 | 12 | 0 | 0 | 12 | 0 | 0 | 0 | 12 | 0 |
| Add to cart | 1 | 1 | 0 | 2 | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 |
| Purchase | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
| |||||||||||||||||||||||||
The entire session might look something like this, with all of the attribute values and engagement types to be considered marked for scoring.
Affinity score weights
Every time a user interacts with a product, the score of each attribute value is updated by the type of interaction with it as well as when it occurred.
Engagement
In order for the data above to become meaningful, a correlation between the user interaction and an attribute value must first be determined. Today, this is done by assigning a weight to each engagement based on its assumed level of intent and then summing up the total number of engagements per each value.
Depending on the affinity algorithm, defaults weights might be quantified as follows.
- Purchase: 4X
- Add to cart: 3X
- Add to wishlist: 2X
- Product view: 1X
- And more
Understandably, the higher level of intent associated, the greater the weight given to the interaction. For example, making a purchase would receive more weight than adding an item to the cart, which itself, outweighs a simple product view. From there, the occurrence of each interaction is multiplied by the weight.
Engagement score = interaction type weight x attribute value count
So if purchase weight is 4, add to cart is 2, and product view is 1, the total score for the value “color:red” is (1×6) + (2×1) + (4×1) = 12.
| Weight | Color | |||
| Green | Red | Blue | ||
| Product view | 1 | 4 | 6 | 2 |
| Add to cart | 2 | 1 | 1 | 0 |
| Purchase | 4 | 0 | 1 | 0 |
| Score | 0 | 0 | 0 | |
These scores can now be used to build an affinity profile, which essentially ranks a list of preferred product colors, categories, brands, and so forth based on the customer’s activity.
Recency
As user behavior and preferences change over time, affinity profiles must be refined with every new pageview, action, and event in real time. Therefore, the recency of each interaction is also taken into account, ensuring the algorithm favors newer activity over older data.
Three time periods are typically used in scoring:
- Real-time or current browsing session: 8X
- Recent history or in the last month: 2X
- All-time or the last six months 1X
When layering this information into the attribute value score, in addition to multiplying the interaction weight, the recency weight is also multiplied.
Recency score = recency weight (interaction weight x attribute value count)
Assuming the same user referenced above comes back to the site two weeks later and purchases the green t-shirt previously abandoned in their cart, the total score for “color: green” would be 2[(1×4) + (2×1) + (4×0)] + 8(4×1) = 44.
| Attribute | Color | ||||
| Recency | Value: | Weight: | Green | Red | Blue |
| Recent History (weight = 2) | Product view | 1 | 4 | 6 | 2 |
| Add to cart | 2 | 1 | 1 | 0 | |
| Purchase | 4 | 0 | 1 | 0 | |
| Score | 6x2=12 | 12x2=24 | 2x2=4 | ||
| Real Time (weight = 8) | Purchase | 4 | 1 | 0 | 0 |
| Score | 4x8=32 | 0 | 0 | ||
| Total Score | 44 | 24 | 4 | ||
| Recency: Recent History (weight = 2) | |||
|---|---|---|---|
| Attribute: | Color: | ||
| Green | Red | Blue | |
| Product View Weight: 1 | 4 | 6 | 2 |
| Add to Cart Weight: 1 | 1 | 1 | 0 |
| Purchase Weight: 1 | 0 | 1 | 0 |
| Score | 6x2=12 | 12x2=24 | 2x2=4 |
| Recency: Real Time (weight = 4) | |||
| Attribute: | Color | ||
| Green | Red | Blue | |
| Purchase Weight: 4 | 0 | 1 | 0 |
| Score | 4x8=32 | 0 | 0 |
| Total Score | 44 | 24 | 4 |
Now the affinity profile reflects two strong scores (engagement and recency), enabling us to showcase products the user is more likely to engage with at any given moment in time. And through the normalization of site data, can even uncover “long tail” attributes correlated with a purchase, ensuring results aren’t skewed by demoting frequently-seen or always-popular attributes.
Releasing affinity into the wild
The straightforward method of affinity calculation described above is simple and effective – it leverages available product metadata to better uncover relationships between attributes from different product fields based on the two light formulas above. This makes it easy to communicate to stakeholders and thus emphasize the importance of good-quality attributes in the product feed – it also incorporates newly released products naturally, without the need for any additional setup or configuration. But the future of affinities is a lot more flexible, thanks to the help of machine learning, which introduces opportunities for increased ranking power and more complex correlations to be uncovered.
These smart affinities can adjust the variables used in calculating scores, as opposed to leveraging the same formula with a static weighting system for all visitors. For example, by adjusting the weight of one attribute to focus on long-term behavior while another is geared toward the current session. Trained using past customer sessions which culminated in conversion, Deep Learning models can assign weights to different interactions and time scopes for each attribute as well as surface correlations between attributes. Then, based on a real-time user session, it can rank an attribute value, say color, by the probability of being added to the cart or purchased, even for colors or brands the individual hasn’t been exposed to before. And through a greater degree of data normalization, critical contextual nuances such as the type of site and product offering, date, and time, will all be taken into consideration during calculations.
You could say, affinity modeling is becoming significantly more personalized. And with such much variability, teams need a lot more visibility into how affinities are generated, analyzed, and actioned. Today, most affinity data exists in a black box, meaning those leveraging it to optimize their personalization efforts have very little insight into how the algorithm at work calculated an affinity score. But “this is your affinity score, take it or leave it” isn’t good enough anymore. All of the data around affinities and attributes should be exposed, customizable, and personalized depending on the unique needs of the business
The beauty of user affinity
The only way to unleash the full power of user affinities for predicting what an individual wants is through exposing and providing as much control over that information, as well as how it’s used, as possible. Therefore, it’s important to partner with a technology provider that will allow you to not only play with all of user affinity’s variables and leverage them in relative verbose ways, but also understand the output of those efforts per campaign.