The Bayesian Approach to A/B Testing
Known for being less restrictive, highly intuitive, and more reliable, let's dive into the math behind the Bayesian Approach to statistical inference and find out why.

![]() Summarize this articleHere’s what you need to know:
Summarize this articleHere’s what you need to know:
- The Bayesian approach is a newer, more efficient statistical method for A/B testing compared to the traditional Frequentist approach. It’s less restrictive, more intuitive, and more reliable because it uses a probability distribution to represent the click-through rate of a variation, and this distribution is updated as more data is collected. This means the Bayesian approach can make more accurate decisions with less data.
- The Bayesian approach tackles the Explore-Exploit dilemma in A/B testing, which is the challenge of balancing collecting more data with using the data you already have. It does this by automatically allocating more traffic to the variation that’s performing better.
- Another benefit is that the Bayesian approach is incremental, meaning you can see the results of your A/B test at any time and decide whether to continue the test. This is in contrast to the Frequentist approach, which requires you to set a fixed sample size before you start the test.
- Overall, the Bayesian approach is more powerful and flexible than the Frequentist approach, making it increasingly popular in the A/B testing industry.
The applications of A/B testing are age-old and spread across industries, from medical drug testing to optimizing experiences within eCommerce. But as the tools used to make informed decisions based on collected data continue to evolve, so too has the best approach.
Once universally accepted, the Frequentist Approach to statistical inference in A/B testing scenarios is now being replaced by a new gold standard. Also based on the foundation of Hypothesis Testing, the Bayesian Approach is known for its less restrictive, highly intuitive, and more reliable nature. While Dynamic Yield has already written about our feelings on the matter, my goal is to dive into the numbers behind the Bayesians school of thought, performing the appropriate derivations where necessary.
Founding Philosophy Of Bayesian Methods:
In a Bayesian approach, everything is a random variable, and by extension, has probability distribution and parameters.
In Frequentist, if we want to model the click-through rate of a group, we try to find its mean and its variance, which act as the parameters. And to find these parameters, we collect sample data, write down likelihood, and then maximize it with respect to the parameters. We go on to build confidence intervals around this Maximum Likelihood click-through rate to quantify the uncertainty around where the real mean would lie.
In Bayesian, the real mean is a distribution, but the observations are fixed, which models real life behavior much better. To be more precise, in the case of a Bernoulli distribution, the probability mass function (pmf) is defined as:


with π being the probability for clicking.
Here, according to the Bayesian approach, π should also have a distribution of its own, its own parameters, etc.
Mean Probability Distribution & its Parameters:
To calculate the mean click-through rate, similar to the Maximum Likelihood mean value in a traditional A/B test, we try to solve for the value π in the below equation:

Where X = the observed data.
We apply the good old Bayesian conditional probability equation:


Here, p(X) can be treated as a normalizing constant, given its independence from π.
Therefore:

p(π) = probability of click before the experiment began – the prior
p(X|π) = observed data samples – the likelihood
p(π|X) = probability of click after observing the sample – the posterior
Prior, Likelihood & Posterior Probability Distributions:
We can calculate the p(X) value (probability of click-through) given the observed sample data is a product of prior and likelihood. Here, prior probability is the probability to click on a variation before any sample data is collected (this would be the historical average of an experiment, or in the absence of any data, can be equated to a uniform distribution), and likelihood, on the other hand, the probability distribution of the collected sample data.
To solve this equation, we exploit a concept called Conjugate Prior. In Bayesian probability theory, if the posterior distribution has the same probability distribution as the prior probability distribution given a likelihood function, then the prior and posterior are called conjugate distributions. The prior is called a conjugate prior for the likelihood function.
In our case, if the likelihood function is Bernoulli distributed, choosing a beta prior over the mean will ensure the posterior distribution is also beta distributed. In essence, the beta distribution is a conjugate prior for the likelihood that is Bernoulli distributed!
Let’s see how exploiting this concept helps us solve the posterior probability for both continuous and binary variables.
Binary Variables:
As we are dealing with a Bernoulli distribution, we only have to deal with one random variable (π). Assuming our likelihood function follows a prior-beta distribution:

Also assuming the experiment begins with no prejudice, a beta distribution for the prior with α=1; β=1 would be a good starting point as beta (1,1) is a uniform distribution:

Grouping the similar terms together:


We can see the posterior is simply a beta distribution of the form:

Where:


Which is the same as our prior probability distribution:

Thus, confirming the conjugate priors concept for binary outcomes.
To solve for a posterior probability for binary outcomes, the blueprint would be:
- π ~ Beta (1,1): assume the prior distribution is uniform
- Sample x1
- π ~ Beta (1+x1 ,1+1- x1): update the beta distribution to account for the sample observed data
- Sample x2
- π ~ Beta (1+x2 ,1+2- x2)
- Repeat from Step 2
In the end, we reach a beta distribution that progresses from a uniform distribution to a skinny, normal distribution.
The following code, implemented in Python, will allow you to more easily visualize the progression, effectively demonstrating how the Bayesian probability changes over time as the number of samples increase
from __future__ import print_function, division
#! usr/bin/env python"
__author__ = "SivaGabbi"
__copyright__ = "Copyright 2019, Dynamic Yield"
from builtins import rangev
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import beta
NUM_TRIALS = 2000
CLICK_PROBABILITIES = [0.35,0.75]
class Variation(object):
def __init__(self, p):
self.p = p
self.a = 1
self.b = 1
def showVariation(self):
return np.random.random() < self.p
def sampleVariation(self):
return np.random.beta(self.a, self.b)
def updateVariation(self, x):
self.a += x
self.b += 1 - x
def plot(variations, trial):
x = np.linspace(0, 1, 200)
for b in variations:
y = beta.pdf(x, b.a, b.b)
plt.plot(x, y, label="real p: %.4f" % b.p)
plt.title("variation distributions after %s trials" % trial)
plt.legend()
plt.show()
def experiment():
variations = [Variation(p) for p in CLICK_PROBABILITIES]
sample_points = [5,10,20,50,100,200,500,1000,1500,1999]
for i in range(NUM_TRIALS):
# take a sample from each variation
bestv = None
maxsample = -1
allsamples = []
for v in variations:
sample = v.sampleVariation()
allsamples.append("%.4f" % sample)
if sample > maxsample:
maxsample = sample
bestv = v
if i in sample_points:
print("current samples: %s" % allsamples)
plot(variations, i)
# show the variation with the largest sample
x = bestv.showVariation()
# update the distribution for the variation which was just sampled
bestv.updateVariation(x)
if __name__ == "__main__":
experiment()
The progression of π over time can be seen as:

Continuous Variables:
While the binary variables cover events like click-throughs, some of the A/B testing is done on continuous variables such as revenue, order value, etc. We would follow a similar path as laid out for binary variables and exploit the concept of conjugate priors. But instead of working with a beta prior, we will now work with a gamma prior and normal likelihood function, resulting in a gamma posterior.
Discrete Variables:
For optimizing metrics that are discrete, such as the number of purchases, pageviews, and so on, we work with a gamma prior and Poisson likelihood. Again, resulting in a gamma posterior.
Dynamic Allocation / Explore-Exploit Dilemma / Multi-Arm Bandit:
Imagine you are at a casino and out of two slot machines, you pick one and win 3/3 times played. What would your next move be? Would you continue to play with the machine that has proven to win or try the other one?
This situation precisely sums up the Explore-Exploit dilemma – the choice between gathering more data and maximizing returns, which we already described closely applies to A/B testing.
In a traditional A/B test, because you assign a percentage of the traffic, there is no option to exploit the data, i.e. incrementally assign more traffic to the winning variation.
Let’s see how this is accomplished in a Bayesian setting.
In short, sampling completely takes care of the Explore-Exploit dilemma for us in a Bayesian test. Say you have distributed traffic randomly between two variations (blue and orange) and reached the following posterior probability distribution for both:
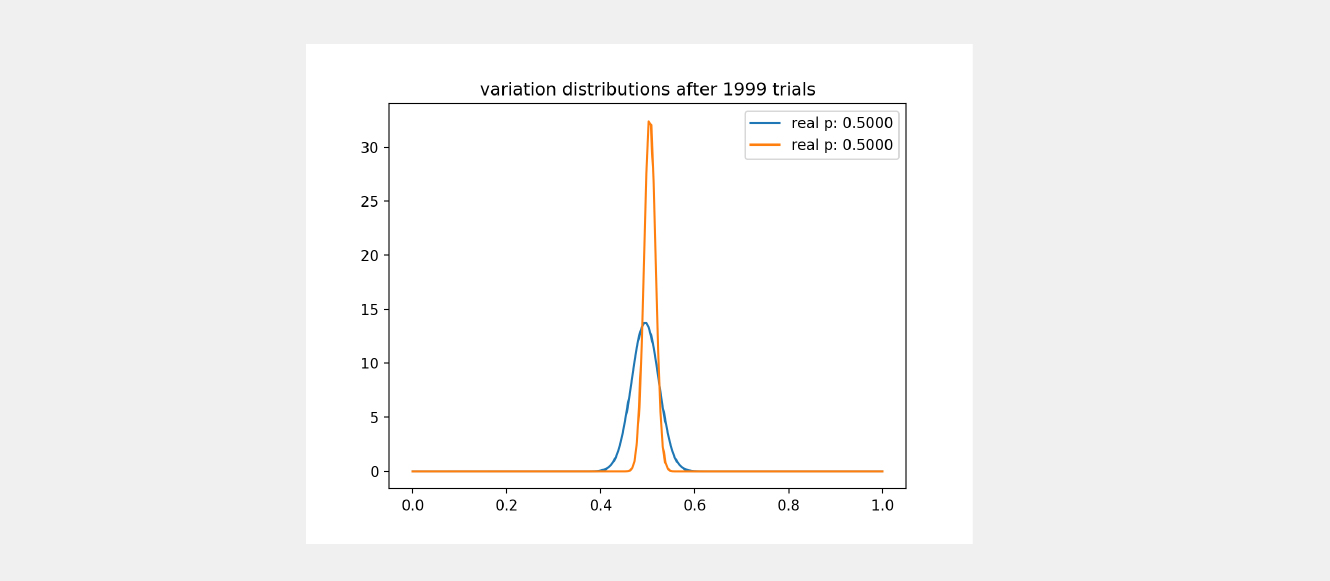
As can be seen, the orange variation is clearly sampled much more than the blue variation. And how do we acknowledge this? The variance! We saw earlier that a posterior probability gets skinnier with more sample data, so given that the blue variation is still chubbier, we can conclude it is not sampled enough.
At this point, if we decide to randomly sample two points, one from each variation, and compare them both, what are the chances the orange variation would be higher?
If the sample from the blue variation comes from the right half of the plot, then it would have better probability to be higher
If the sample from the blue variation comes from the left half of the plot, then it would likely be lower than the orange variation
What happens if we decide on the variation to show next based on which has the higher value in this random sampling?
→ If the blue variation wins, it would then be shown next to the audience, furthering its sampling while also narrowing around a fixed probability for its true mean value. Here, we see two additional possibilities:
Its final probability > orange variation’s probability: If the sampling is continued, the blue variation would continue winning
Its final probability < orange variation’s probability: Orange variation would be sampled more and continue being shown
→ If the blue variation loses, the orange variation is shown
Therefore, sampling takes care of the Explore-Exploit dilemma for us, always making the best decision on our behalf.
Declaring a winner:
Once the posterior distributions are mapped for the variations, to conclude a winner, you sample a large amount of observations. Hypothetically, let’s say you sample 1000 times from two variations and 999 times out of 1,000 you see the orange variation having higher probability:

The probability that variation orange is better than variation blue will be (999/1000) * 100, which is 99.9%.
At Dynamic Yield, we sample 300,000 times from every variation to calculate the Probability to Be Best (P2BB).
Bayesian Wrap Up:
Recapping everything that has been laid out so far:
Bayesian A/B testing converges quicker than a traditional A/B test with smaller sample audience data because of its less restrictive assumptions.
Achieving significance is ‘incremental’ by nature in Bayesian A/B testing. You can check the values at any time and decide to discontinue the experiment.
Negligible chance of a false positive error.
Explore-Exploit strategy in Bayesian testing does not leave money on the table.
To conclude, the industry is moving toward the Bayesian framework as it is a simpler, less restrictive, highly intuitive, and more reliable approach to A/B testing. In fact, Dynamic Yield has made the move to a Bayesian statistical engine, not only for binary objectives such as goal conversion rate and CTR but also for non-binary objectives such as Revenue Per User.
If you’d like to learn more about the issues presented in the Frequentist Approach, check out this blog post.