![]()
Most experimentation platforms have built-in analytics to track all relevant metrics and KPIs. But before analyzing an A/B test report, it is important that you understand the following two important metrics.
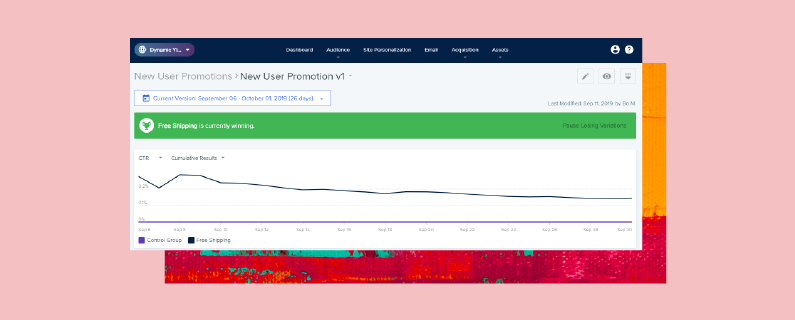
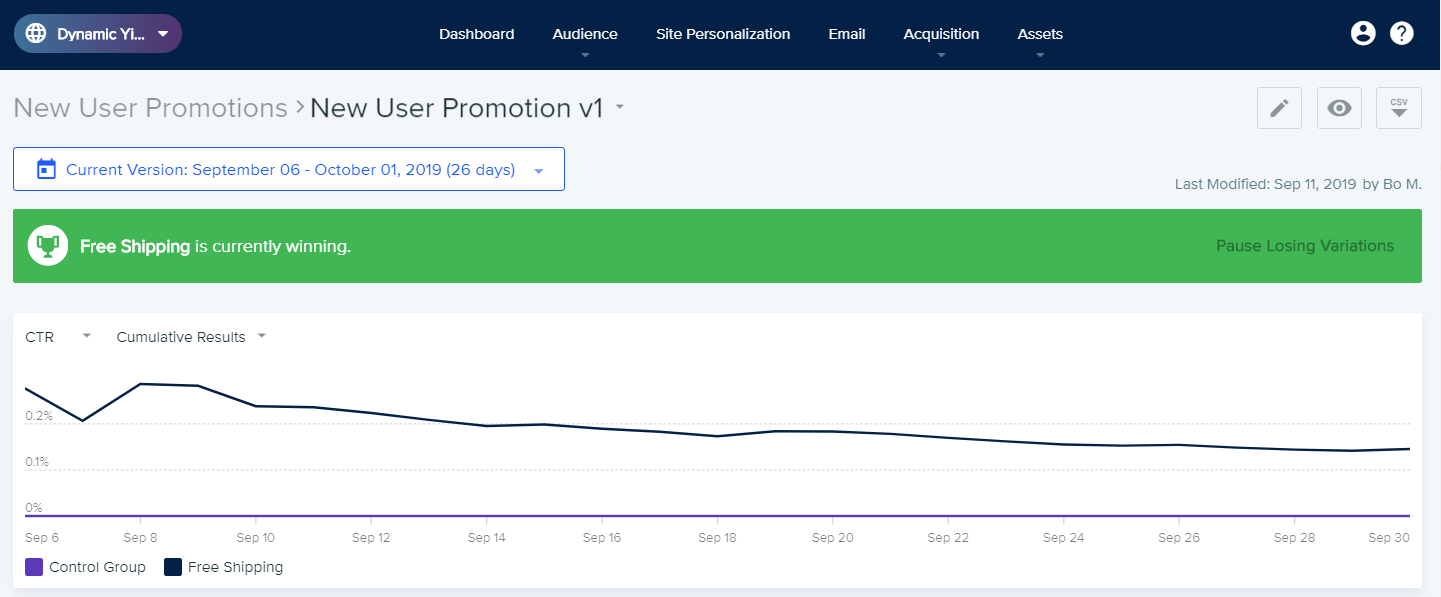
Start by checking the A/B test results to see if a winner has been declared, or for other information such as which variation is currently winning. If your experimentation does not provide the Probability to Be Best metric, use our Bayesian A/B Testing Calculator to examine the data and look for statistically significant results.
Typically, a winner will be declared if the following conditions are met:
While the winners of each test are based on the primary metric, some experimentation platforms like Dynamic Yield also measure additional metrics called secondary metrics. We recommend analyzing secondary metrics before concluding the experiment and applying the winning variation to all users for a few reasons:
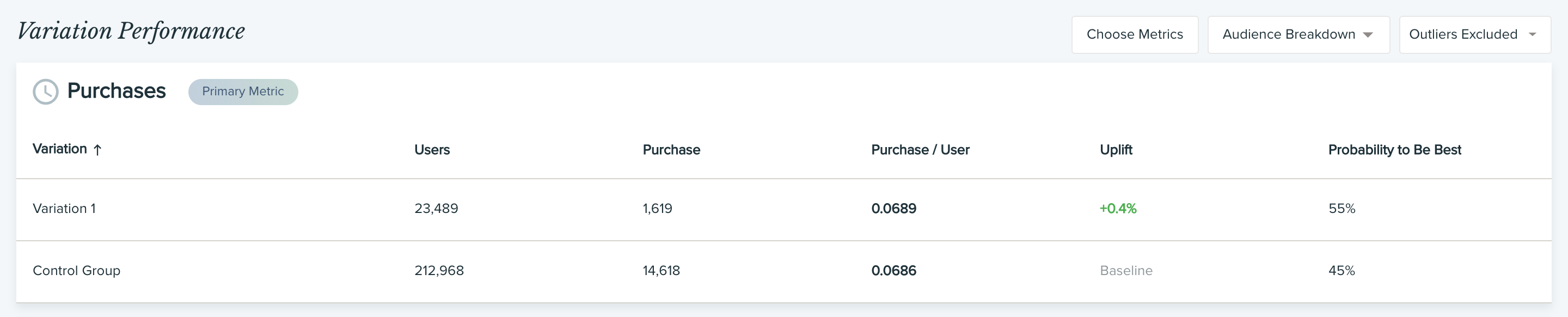
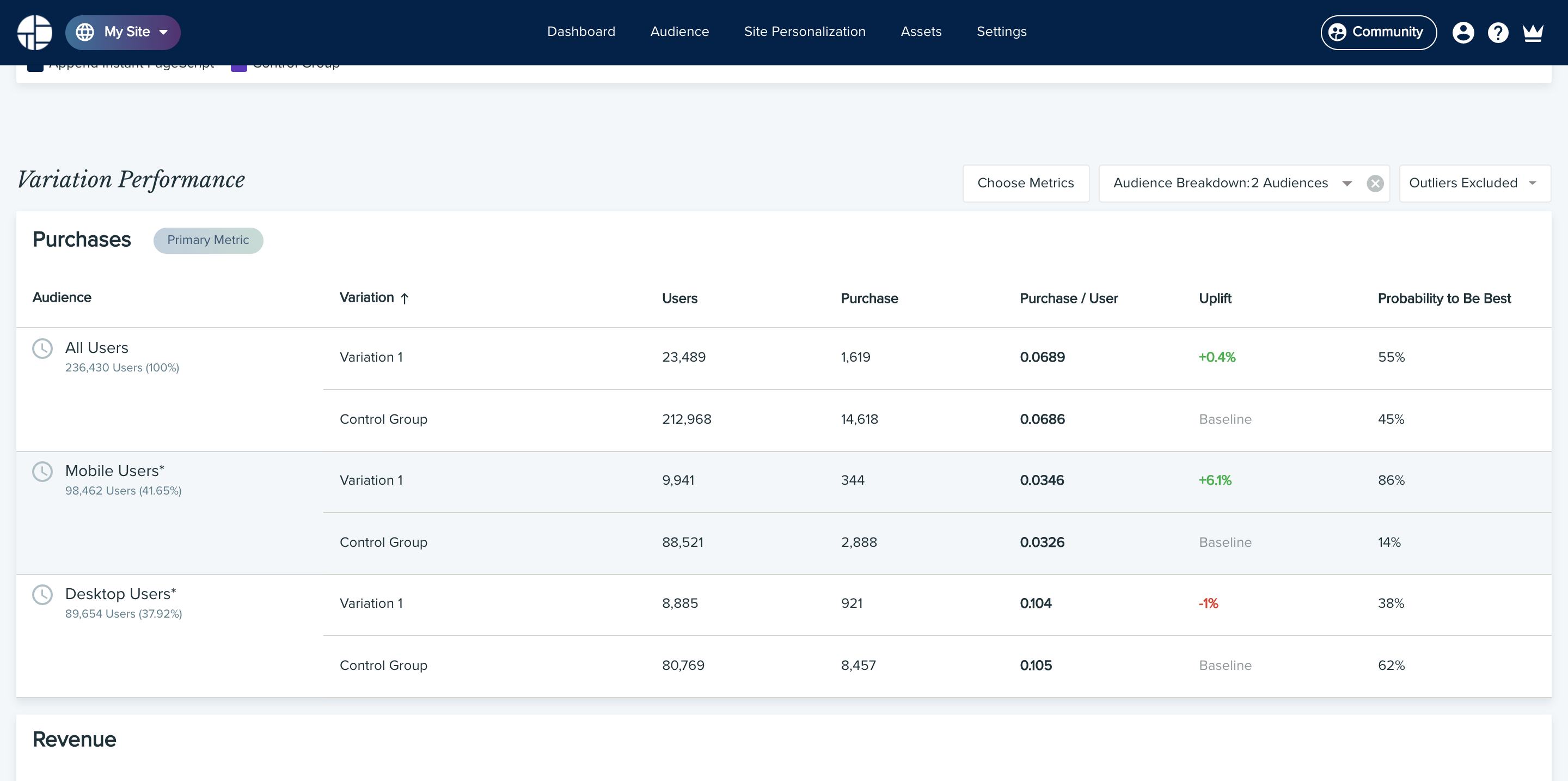
For each secondary metric, we suggest looking at the uplift and Probability to Be Best scores to see how each variation performed.
After your analysis, you can determine if you should serve all of your traffic with the winning variation, or adjust your allocation based on what you have learned.
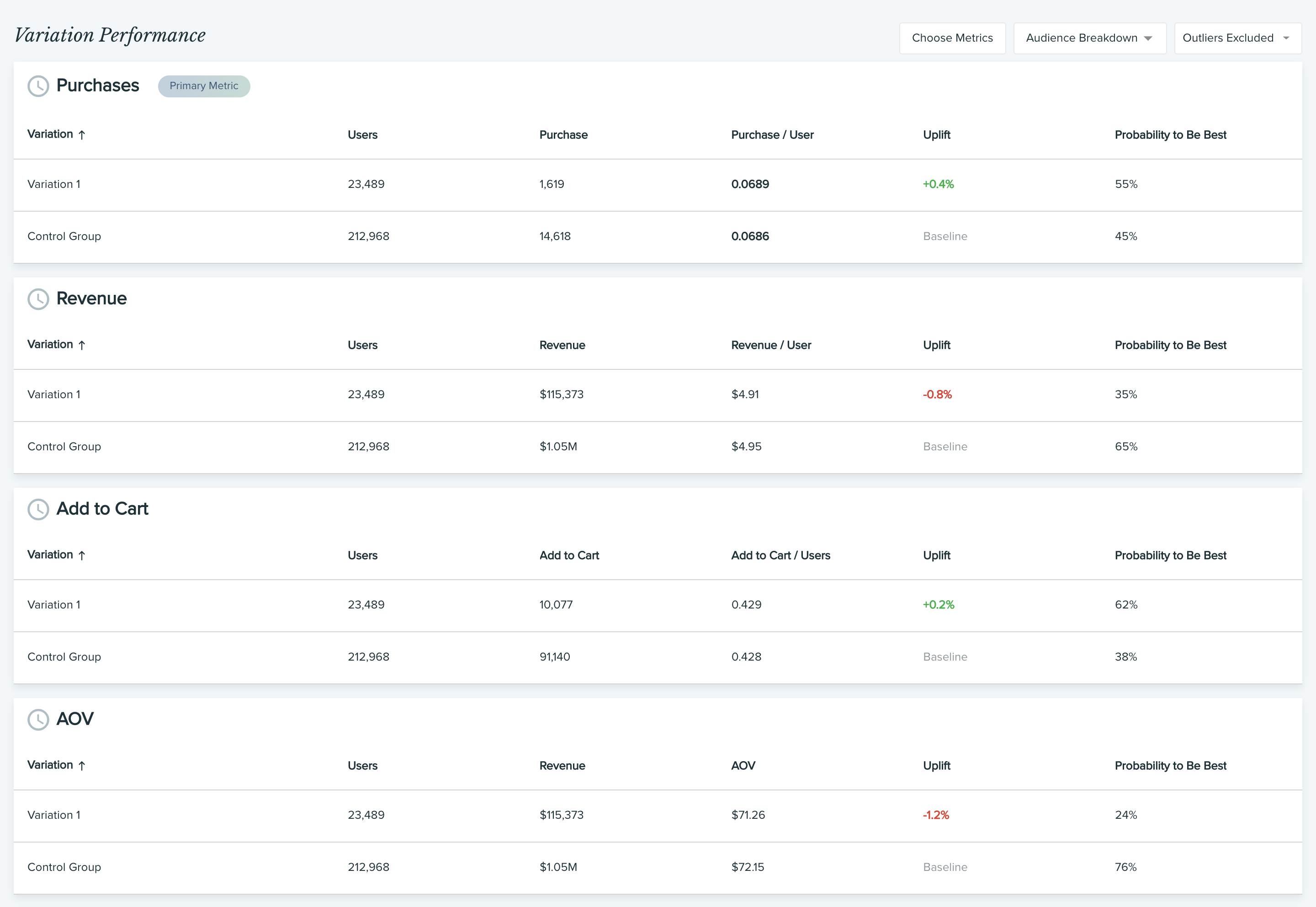
Another good way to dig deeper is to break your results down by audience. This can help answer questions such as:
I recommend selecting audiences that are meaningful to your business, as well as audiences that are likely to have different user behaviors and intent signals.
Once again, for each audience, look at the uplift and Probability to Be Best scores to see how each variation performed. After your analysis, you can determine if you should serve all of your traffic with the winning variation, or adjust your allocation based on what you have learned.
There’s no doubt that CRO and A/B testing works, long relied on for producing massive uplifts in conversion and revenue for those who properly identify the best possible variation for site visitors. However, the truth is that as delivering personalized interactions becomes more intrinsic to the customer experience, experiments that don’t take into consideration the unique conditions of individual audiences will end up with inconclusive results and statistical significance will become harder to achieve.
In this complex new world of personalization where one-to-one supersedes a one-to-many approach, “average users” can no longer speak for “all visitors.” That means previous ways of uncovering and serving the best experiences won’t suffice anymore, despite following best practices around sample size creation, hypotheses development, and KPI optimization.
Today, instead of accepting test results at face value and deploying variations expected to perform best overall for all users, marketers must understand that in doing so, they’ll be compromising the experience for another portion of visitors. Because there will always be segments of visitors for whom the winning variation is not optimal. Only after recognizing this flaw in test analysis and execution does it become clear that losing A/B tests can actually end up as winners, and that hidden opportunities once thought meaningless may actually bare the most fruit through a modernized, personal way of thinking.
In the example below, find real results from an experiment which was live for about 30 days. Almost in a draw, at first glance, it appears as though the control is outperforming the challenger.
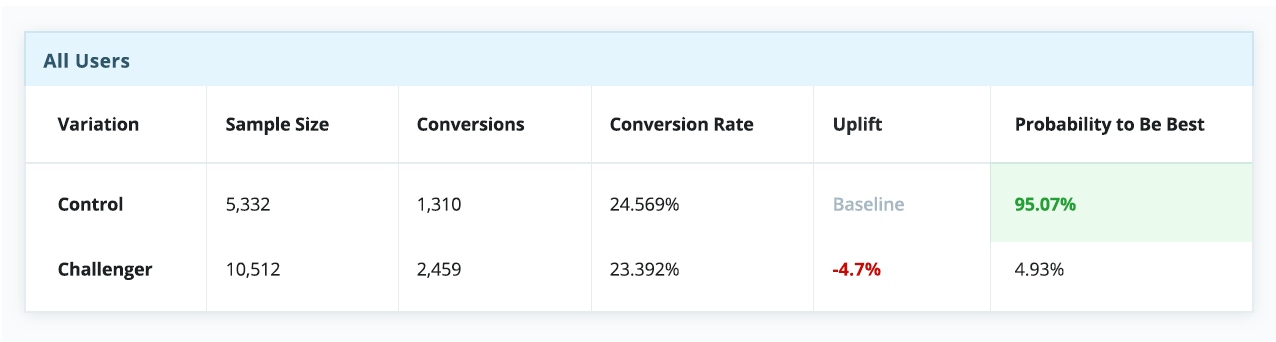
However, when breaking down the experiment report by devices, a relatively basic and straightforward measure, there’s a completely different story, indicating the control is a winner on desktop, but is dramatically outperformed by the challenger on both tablet and mobile.
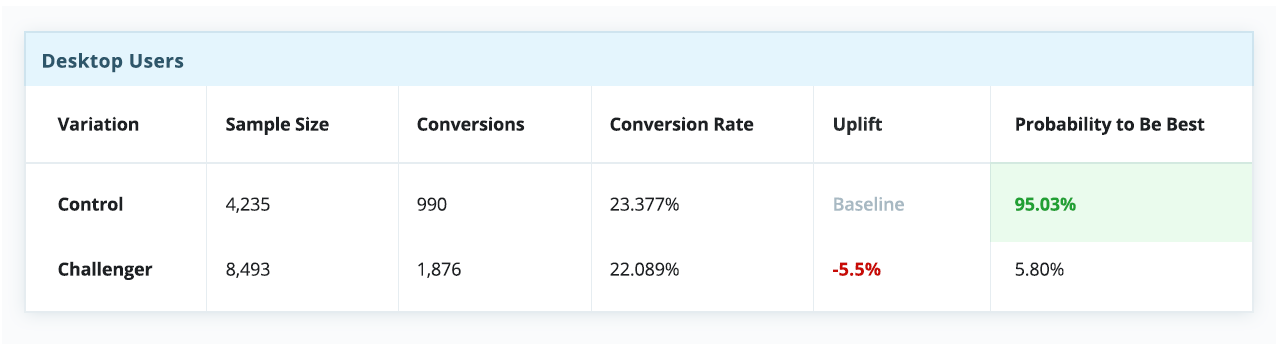
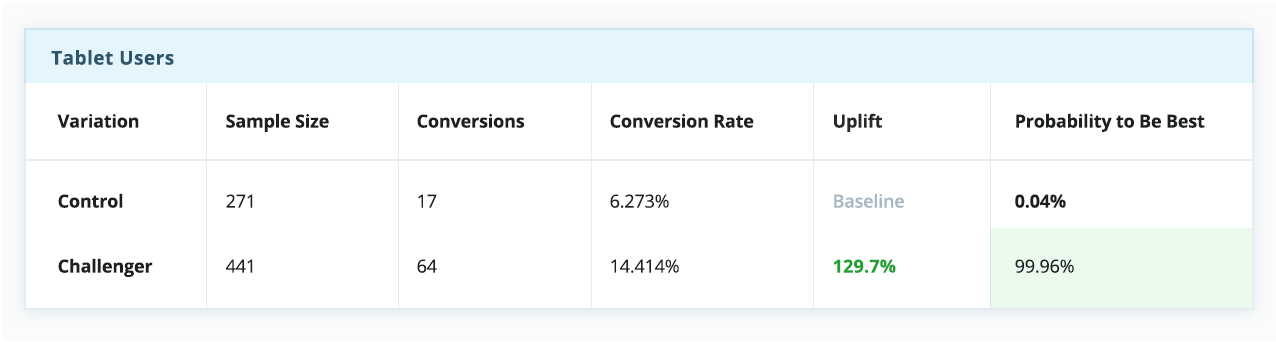
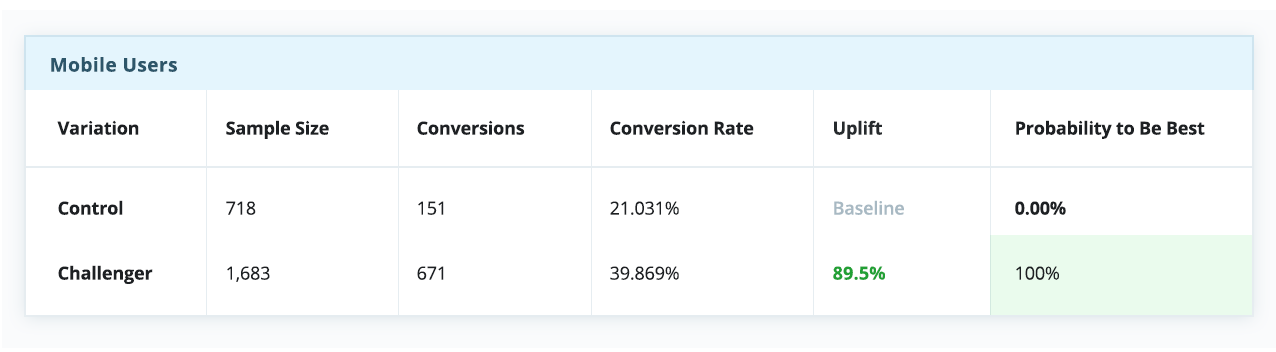
In the above testing scenario, had a “winner takes all” strategy been set (which many faithfully do), the entire visitor pool would have unknowingly been served with a compromised experience that is “optimized” for an average user, despite a clear preference for the challenger across mobile web and tablet.
In another example, while the control group proves subpar on average, further analysis concludes it should, in fact, still be allocated to “All other users,” leaving the much larger “Direct Traffic” segment to receive its preference, variation two.
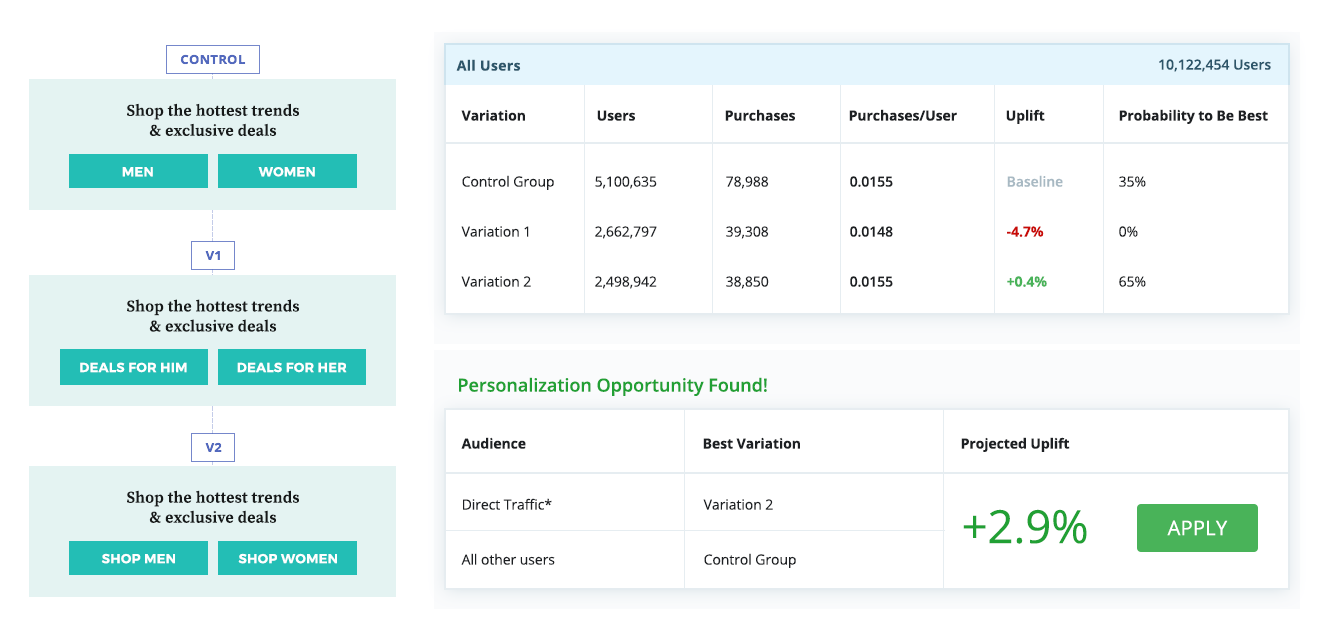
These references illustrate the importance of discovering the impact of test actions on different audience groups when running experiments, no matter how the segment is defined. Only after taking the time to thoroughly analyze the results of one’s experiments for different segments can deeper optimization opportunities be identified, even for tests that are failing to produce uplifts for the average user (which doesn’t actually exist).
While some of these scenarios won’t require more than a quick analysis on the part of a CRO Specialist, with busy testing cycles and constantly changing priorities, carving out the time to do so doesn’t always happen. This problem only becomes exasperated as the number of tests, variations, and segments increases, making analysis an incredibly data-heavy task.
Knowing this, how can one go back to a life of accepting the status quo, taking results at face value, and discarding treatments unnecessarily?







