![]()
The future of personalization and product recommendations will be heavily shaped by deep learning (DL) and its ability to predict the next natural item or product for a visitor.
In this post, I’ll walk through some of the main concepts behind deep learning, why it is starting to become more widely adopted, and how its highly effective implementation in natural language processing (NLP) is being adapted to DL-based recommendation engines.
In the last decade, the scientific world has been thrilled by the tremendous success of deep learning (DL) methods, playing a major role in how artificial intelligence (AI) has flourished over the past few years. The most notable of these revolutions have been made possible by DL in computer vision and natural language processing (NLP).
Deep learning is a subfield of machine learning (ML) concerned with algorithms inspired by the structure and function of the brain. When data scientists say deep learning, they are referring to a family of algorithms that abstractionally look and work as the human neural network does. Essentially, there are a number of neuron nodes connected together like a web, each receiving input information, processing it, and then outputting processed information to nearby nodes.
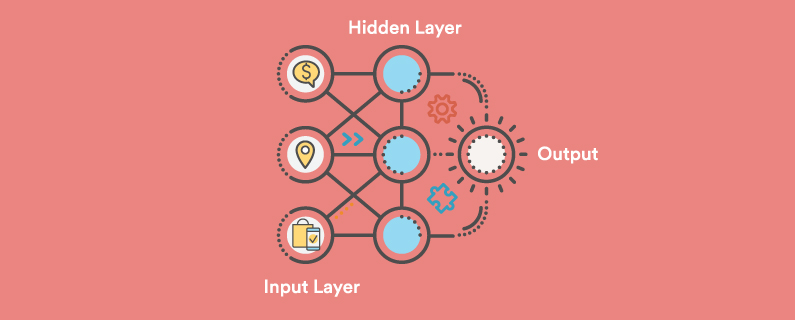
The architecture of all deep learning models includes a multiple-layers structure, with every layer consisting of nodes that perform a particular mathematical operation, which is called an activation function.
It’s common to distinguish three types of layers: input, hidden, and output (Figure 1).
There are multiple reasons why deep learning is becoming more widely adopted, the first being great consolidation between the computational capacity required by DL and consistent growth in the power of cloud-based machines.
While the vast majority of traditional machine learning models analyze data in a linear way, the deep learning system’s architecture enables the processing of data in a nonlinear way. This grants deep learning algorithms the possibility to be more effective in mining valuable information from the data.
But the biggest advantage of deep learning is its ability to construct additional features in an automatic manner. Features are variables such as age, region, day of the week, etc. that are used to predict behavior, like a purchase. In contrast to traditional machine learning, deep learning builds many new features based on different, often unexplainable (aka black box), combinations from an initial set of given features.
Among the main reasons, only with enough data do deep learning algorithms have the advantage over traditional machine learning algorithms, which require less data and is, therefore, preferable in many instances.
Deep learning techniques also need more time for training, and as a result, a higher capability of infrastructure to handle the required calculations, which can increase server costs. Finally, the interpretability of DL-based decisions is lower than that of classic ML algorithms as multiple transformations during modeling make it difficult to understand the pure impact of input information on the output result.
Recently, deep learning has stepped into the world of recommendation architectures, thanks to the perfect parallel between natural language processing and recommender frameworks. Both domains have a sequential nature and are thirsty to understand what the next natural item is in a sequence.
Take Gmail’s Smart Compose feature, which has already proven deep learning’s effectiveness at predicting the next word in a sentence. Now, imagine each word typed when composing an email is a list of products a visitor has engaged with – the same exact concept can be applied to recommendations. And while this unlocks an extremely powerful tool for eCommerce brands, it’s still only the very beginning, with a wide range of opportunities on the forefront being made available to handle the challenges of recommendations in the big data space.
Deep learning’s ability to capture non-linear and non-trivial relationships between users and products as well as incorporate rich information makes it almost limitless, producing a quality of recommendations the industry has yet to achieve until now.
Such information includes, but is not limited to:
When looking at the direction of research and current developments taking place in deep learning, its use in powering recommendation engines can be divided into three categories.
Content-based recommendations make full use of the user’s profile and description of the product to generate recommended items.
Collaborative filtering-based recommendations leverage the user’s past behavior and preference data, without personal information such as the user’s rating of the item, to generate recommended items.
Hybrid method recommendations seek to obtain the best recommendation results by combining content and collaborative filtering-based recommendation methods.
Collaborative filtering is a common approach to deliver personalized recommendations, capable of accurately recommending a wide range of products without needing to understand the essence of a particular item. However, deep learning provides a whole new level of sophistication.
Borrowing the natural learning processing technique called word2vec, or in eCommerce, item2vec, the deep learning algorithms work to exploit the co-occurrence of items in a user’s browsing history and overall, generate recommendations at a higher accuracy.
Being a deep learning-based method, item2vec also has a number of technical benefits:
Here’s a little more about how it works.
Item2vec is a representation of word by numeric vector that is obtained from deep learning modeling of items co-occurrence. Such vector encodes enormously important information about other neighboring items that co-occur with a specific item. These neighbor items are called context (Figure 3).
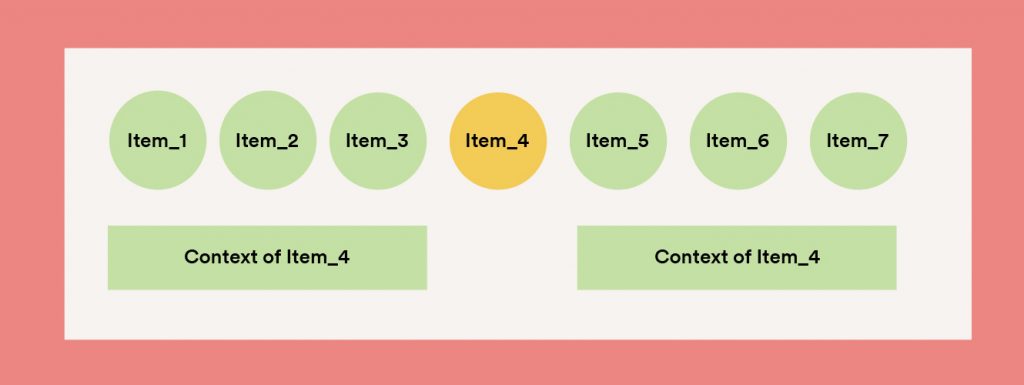
With item2vec, an item can be inferred from the context–items that tend to be around it – similar surroundings of two items implies similarity in consuming patterns of items themselves. And the more times two particular items appear in similar contexts, the closer their representative vectors will be.
Now, when each item from a catalog is represented by numeric vector and vectors’ similarity reflects items’ contextual similarity, we are ready to serve the main “dish,” so to speak, with the most relevant items based on the user’s recent interests. This can be easily done by finding items with vectors similar to vectors of recently engaged products. Such similarity between vectors is called Cosine Similarity, and as items with the highest cosine similarity are expected to be very relevant, they should be recommended to the user.
Companies today need to better predict the next-best-product or piece of content and dynamically recommend and refine offers if they want to enhance the customer experience and continue to generate meaningful revenue.
As the world continues to move towards these advanced algorithms, we expect deep learning will become the industry’s go to-strategy, replacing the limited ranking power of collaborative filtering with that of more personalized recommendations in the very near future.

