Guidelines for running effective Bayesian A/B tests
In this post, we describe the basic ideas behind Bayesian statistics and how they feed into business decisions you will need to make at the end of a test.


Both professor Ron Kenett and David Steinberg of KPA Group sat down to talk to more candidly about some of the topics discussed in this article.
Read the full transcript
So the straightforward one is comparing two options, A and B. The more complex ones can compare combinations. So you could have A, which is a combination of two or three things, and B, which is a different combination, and C, which is still another combination. And if you apply methodology which is based on a statistical approach called design of experiments, in one test, you can learn about several factors, the effect of several factors.
So when you’re thinking about setting up an AB test, invariably, you have some alternatives that you wanna compare, and the tests usually follow methodology that’s been developed over many years in the statistical literature. What you’d like is to make sure that the people who see option A are, in some sense, as similar as possible to those who see option B. And it’s become well-established in the scientific literature, going back to work of the statistician Ronald Fisher, about 100 years ago, that the best way to do that is to make sure that you randomly allocate who gets which of the options that you want to compare.
So if you’re gonna start an experiment, you have to think about what are the options that are on the table. What do you want to compare? You have to have an engine at your disposal, framework that’s gonna let you make those random allocations. So if someone comes into your website, they’re not just gonna get a landing page, you have to decide what landing page they’re gonna get. You control that, and you want to control that by allocating it at random between the groups. That’s what’s gonna guarantee having a fair comparison.
Now, in order to validate the data that you’re capturing, you must ensure, for example, that this random allocation occurs. Because if you give the young people version A and the older people version B, and you see a difference, you will never know if it’s due to the age or to the web page design. That’s called confounding. So the random allocation, in a sense, establishes some causality on what is really impacting user behavior.
There are a number of ways that you can go about analyzing the data that you get from an AB test. Classical statistics takes a view that there is some true value for that KPI, and for example, it might be common if you’re comparing two options, to start with a framework that says both options are identical unless we get evidence that shows that they’re different. The Bayesian analyses take a somewhat different viewpoint, and rather than saying there’s some value, we just don’t know what it is, describe that value by putting a probability distribution on it. So you get more and more data. The probability distribution gets tighter and tighter about focusing on what we’ve now learned so that we have better information. It often gives a much more intuitive way, in particular in terms of business decisions, for looking at how to characterize what we know, rather than saying, “Well, it could be between this and this, and either it is, or it isn’t.” That’s sort of the classical way. And we give a more gradated answer by saying, “Well, this is the most likely.” And then there’s a distribution that describes how unlikely values become as we move away from what we think is the most likely value.
Bayesian statistics give you a, I think, a much more intuitive and natural way to express those understandings that you get at the end of an experiment in terms of say, what’s the probability that A is better, what’s the probability that B is better. So you bring in the data, use the data, and now Bayesian inference provides standard rules, and very strictly mathematical rules for taking the data, using that to update your prior to get what’s called a posterior distribution.
The posterior is, this is your current view. This is what you think after having seen the data. What describes your uncertainty about the KPIs after having seen the data, and you combine those two together in order to get your final statement about what it is you think. Can you really state a prior distribution? Is there a defensible way to state what you think in advance? As again, this has certainly been the source of friction between people in the different statistical camps. In the case of most AB tests, you’re getting lots and lots of data, and the data is going to wash out anything that you might’ve thought in the prior. So that for typical AB tests, again, because you have very large data volumes, it no longer becomes, in my mind, very controversial because whatever you put in to get the Bayesian engine going is essentially gonna be washed out by the data. And the data is really going to be the component that dominates what you get in the end.
So sample size is an important question in any study that’s going to be run. Whenever you go out to get the data. How long do I have to run my test? How many visitors to the website do I have to see before I can make conclusions? In order to get a test that gives a complete and honest picture, representative picture, of all the people who are long term gonna be exposed to whatever decisions you make, you wanna make sure that you include everyone within a cycle like that. You don’t wanna stop the test after having seen only visitors on Tuesday and Wednesday. And it may turn out that the decision you made is really catastrophic for those who come in on the weekends. So you always want to make sure that you pick up any potential time-cycles like this. And in terms of the sort of Bayesian descriptions that we were talking about later, I think this really gets to the heart of, in the end, you’re gonna get these posterior distributions that describe your KPIs, and how narrow do you want them to be? The tighter the interval, the more you know.
You can have a tight interval, but if the people who looked at the website and were part of the randomization subgroup, then whatever you’re going to get will not apply to the general group. So you really should work on both fronts. One is, how much information do you have? The tighter the interval, the more informative it is. But also how generalizable is the information that you provide?
Both of these aspects are important, and both of them can be the ones that really are the driver in dictating how large an experiment has to be. A website that has very heavy volume may quickly get to the needed sample size but without being able to see the full representative picture of all the visitors. And of course, it can happen just the other way, that by the time you get enough people in, enough visitors into the site, in order to get to the sample size you need, you’ve already gone through several of those time cycles. And so you have to see how both of these work out and balance against one another.
![]() Summarize this articleHere’s what you need to know:
Summarize this articleHere’s what you need to know:
- A/B testing involves showing different versions of a webpage to different visitors and measuring which version performs better.
- Randomization is key to ensuring that the results of your A/B test are accurate and unbiased.
- It’s important to define your goals and metrics before running an A/B test so that you can measure success.
- Make sure your sample size is large enough to draw statistically significant conclusions from your A/B test results.
- Pay attention to the statistical significance of your results to avoid making decisions based on random fluctuations.
- Iterate on your A/B tests based on the results you learn to continuously improve your website.
A/B testing is a great way to compare alternative experiences or possible modifications to your website or digital properties. By running the two experiences in parallel and deciding at random which visitors land on which version, you get an honest comparison of which one delivers better performance.
Once you get the data from your test, you need reliable and informative ways to summarize them and reach conclusions. The Bayesian approach to doing statistics is a great way to accomplish this.
Here we describe the basic ideas behind Bayesian statistics and how they feed into the business decisions that you will need to make at the end of a test. We first present the approach to data analysis.
Then, we illustrate how data analysis leads to natural solutions for questions such as:
- Which variant drives better results?
- How much better are those results?
- Can we be confident in our conclusion?
- What if we want to test more than two variants?
- What sample size is needed for a Bayesian A/B test?
- Can a test be terminated early if results look clear?
What is Bayesian Statistics?
Bayesian statistics is named after the Reverend Thomas Bayes who lived in Britain in the 18th century and was responsible for proving Bayes Theorem. The guiding principle in Bayesian statistics is that you can use the language of probability to describe anything that we don’t know and want to learn from data. As we will see, this is an ideal language for discussing many of the questions that are most important to business decisions.
When you run an A/B test, the primary goal is to discover which variant is most effective. To do so, you compare the results with the two methods. The Bayesian analysis begins by looking at the KPIs for each of the variants. The data gives us information about their value but always leaves some uncertainty. We describe uncertainty using a probability distribution. We can simulate results from the distribution to understand how it looks.
The histogram in Figure 1. is typical of what you might get from your analysis. It shows the statistical distribution of difference in click-through rate (CTR) between A and B. Most of the curve is to the right of 0, providing evidence that A has a higher CTR. The fraction of the curve to the right of 0 is a great summary of that evidence – it is called the Probability to Be Best (P2BB). In Figure 1., P2BB is 0.699, in favor of version A.
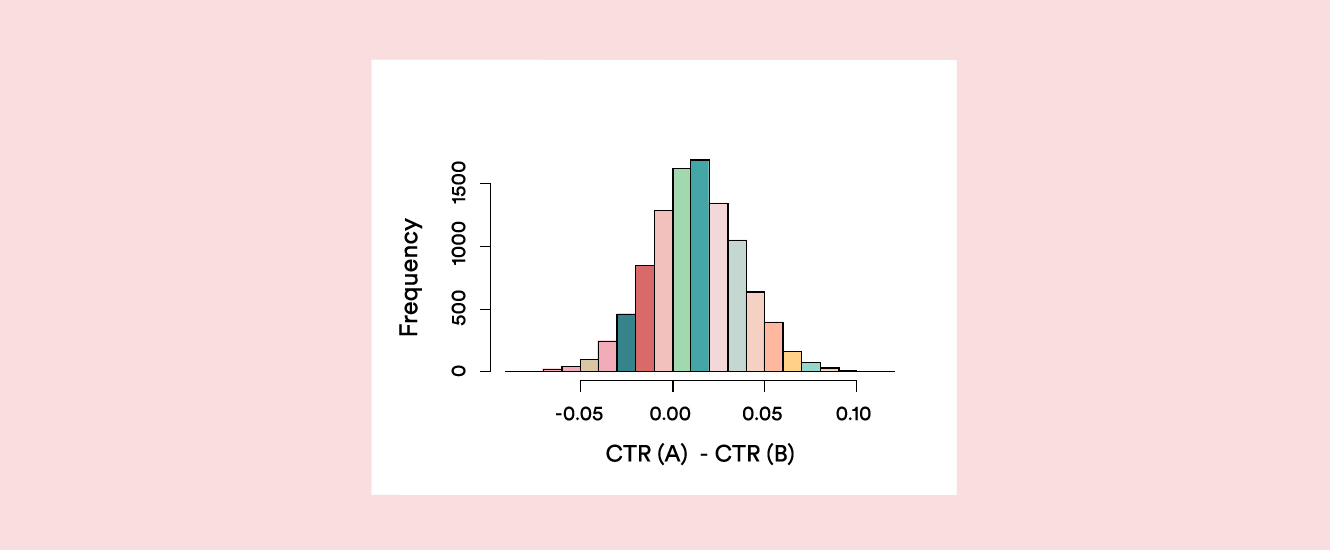
Figure 1: Probability function for the CTR for A minus the CTR for B
If you have three or more variants, it is still easy to compute the probability of being best (P2BB), with probability split into three pieces, one for each variant.
How does Bayesian analysis work?
You need to start the Bayesian engine running with a prior probability distribution that reflects what you think about the KPI before seeing any data. The prior is then combined with the test data to obtain a posterior distribution for each variant. Figure 1. would be the posterior distribution for the difference between the A and B variants – this reflects the current view after having seen the data.
You need the prior to make things work, but when the volume of data is large – and that is almost always the case in A/B tests – the posterior is quickly dominated by the data and virtually “forgets” the prior; so you don’t need to invest too much thought about how to choose the prior. It is possible to work with some standard choices for priors without affecting the analysis.
But can you really state a prior distribution and what you think in advance?
This has certainly been the source of friction between people in the different statistical camps, so it is helpful to contrast the Bayesian summary with the “classical,” Frequentist approach you might have studied in an introductory statistics course. In the classical approach, either A is better than B, B is better than A, or they are identical. The question “what is the probability that A is better” is not part of the lexicon – you can’t give an answer, and in fact, you’re not even permitted to ask the question!
The classical paradigm does use probability, but only to describe the experimental data, not to summarize what you know about a KPI. That’s why you can’t make a summary like “the probability that B gives a positive uplift over A is 98%.
In most A/B tests, you’re getting lots and lots of data. Therefore, it no longer becomes very controversial, because whatever you put in to get the Bayesian engine going is essentially gonna be washed out by that information, which is really going to be the component that dominates what you get in the end. And that’s why we think the Bayesian summaries are so much better suited for business decisions.
For more on the different viewpoints when it comes to the Bayesian vs. Frequentist approach to A/B testing, check out this article.
How should traffic be distributed between variations?
What you’d like is to make sure that the people who see option A are, in some sense, as similar as possible to those who see option B. And it’s become well-established in the scientific literature, going back to work of the statistician Ronald Fisher, about 100 years ago, that the best way to do that is to make sure that you choose the right traffic allocation, or who gets which of the options that you want to compare.
So, you have to think about what are the options that are on the table. What do you want to compare? You have to have an engine at your disposal – a framework that’s gonna let you make those random allocations. If someone comes to your website, they’re not just gonna get a landing page, you have to decide what landing page they’re gonna get. You control that, and you want to control that by allocating it at random between the groups. That’s what’s gonna guarantee having a fair comparison.
In order to validate the data that you’re capturing, you must ensure, for example, that this random allocation occurs. Because if you give the young people version A and the older people version B, and you see a difference, you will never know if it’s due to the age or to the web page design. That’s called confounding. So the random allocation, in a sense, establishes some causality on what is really impacting user behavior.
What length of time is needed to run an a/b test?
In making these decisions, it is important to think about “what might go wrong” with the testing engine. You want your test to be sensitive to possible bugs. Often bugs are related to failures of the random allocation over time so that natural time trends in your KPIs bias the results. If there are weekly trends in your data, then you need to run an A/B test for two weeks to make sure that the engine is successfully handling them. If there are diurnal trends (but not weekly), you can afford to run shorter experiments. There may also be special events that suddenly increase or decrease the number of visitors to your site, or change the composition of visitors, affecting the performance of an experience. You may want to hold off on making any decisions until you see whether such issues have an impact on your results.
The considerations noted above will suggest a minimum time frame for running your experiment that ensures representative coverage in the A/B test of typical future site visitors. Often, these will dictate the length of time for the test.
How large a sample size is needed for a Bayesian test?
The sample size paradigm for Bayesian testing asks how narrow you want your final probability functions to be. You will probably want to focus on the probability function for the difference in KPIs between the two variants, as shown in Figure 1. And you will already have an idea what sort of difference could be important for your business; that gives a guideline for how narrow you want the function to be – the tighter the interval, the more you know.
It’s important to note that you can have a tight interval, but if the people who looked at the website and were part of the randomization subgroup, then whatever you’re going to get will not apply to the general group. So you really should work on both fronts. One is, how much information do you have? The tighter the interval, the more informative it is. But also how generalizable is the information that you provide?
Both of these aspects are important and can be the driver in dictating how large an experiment has to be. A website that has very heavy volume may quickly get to the needed sample size but without being able to see the full representative picture of all the visitors. And this can happen the other way around too, so that by the time you get the sample size you need, you’ve already gone through several time cycles – you have to see how both of these work out and balance against one another.
You will need to provide information on likely values for the KPIs. Often one of the versions is already running, so you can use historical data for this purpose. For new versions, you will need to think about what effect they might have. If the test includes multiple versions, the same ideas apply and the same inputs are needed.
The basic inputs needed to compute a sample size depend on the nature of the KPI:
- For binary KPIs like CTR or installation rate, all you need are the expected rates for each version
- If you are looking at purely continuous KPIs like revenue per conversion, you will need to supply an estimate of both the typical conversion size and the variation in size among those who do convert
- For a “mixed” KPI like revenue per visitor, you will need the average, variation, and an estimate of the fraction who will convert.
There are straightforward formulas you can use to determine the sample size, and also helpful A/B test sample size calculators.
What if there are more than two versions in the test?
The same sample size formulas are relevant, but here we distinguish between two goals: (1) finding the best and (2) showing that the standard version is not the best.
What is different about the second goal?
Suppose you have two new versions that you want to compare to the standard. Your best guess gives almost the same expected KPI to each of the new versions, with both of them improving over the standard. With very similar KPI’s, you will need a large sample to know which of the two new versions is better than the other. But if you expect both to be better than the standard, you can “rule out” the standard version with a much smaller test.
To further illustrate the idea:
The current experience is getting a CTR of 1%. A new version is proposed with the expectation that it will increase the CTR to 1.2%. The expected difference is 0.2%, so you need an A/B test that will tell you what is the true difference to a higher resolution. A good rule of thumb is to aim for a resolution that concentrates 95% of the Posterior Distribution in an interval that is the size of the expected difference.
In this example, that means narrowing down the difference so that you are 95% certain about an interval of length 0.002. To achieve this level of accuracy, you will need a sample of 83,575 visitors to both pages. What if even a 10% improvement in CTR, to 1.1%, is critical? Then you would need to know the difference up to, at most, 0.1%. That will require a sample size of 319,290 for each version.
Now let’s look at an example involving revenue per visitor:
A common scenario (often referred to as the Pareto principle)is that most visitors don’t provide any revenue and, among those who do, a small number of “big fish” pull up the average, and also the standard deviation.
The current landing page has a conversion rate of 1%; on average, converters spend $20; the standard deviation in the purchases of converters is $25. That means the average revenue per visitor is $0.20. Marketing thinks that the new version will bring in more purchasers, upping the conversion rate to 1.2%, but will decrease the proportion of “big fish,” so that the average conversion drops to $19 and the standard deviation to $22.
That translates to an average revenue of $0.228, an expected improvement of $0.028 per visitor. The A/B test will need to be large enough to narrow down the 95% credible interval for the difference in average revenue to no more than the expected difference, i.e. to $0.028. We will need 397,830 visitors to each experience to achieve that level of accuracy.
What if we want a stronger guarantee that we will find the important difference?
We advised above setting the sample size to control the width of the 95% credible interval. It is easy to reduce the chance of missing a valuable change by insisting on a higher level of probability, say 98% or 99%, but at the expense of increasing the sample size.
Can you stop a test early?
The probability that A is better (or worse) than B provides a natural metric to track as the test progresses. And a strong signal from the P2BB statistic can be used to guide early stopping. However, early stopping needs to be done with caution.
First, the Bayesian summary is not completely immune to data peeking. The P2BB will drift up and down during an experiment. This is especially true if there is no difference in performance between the variants, as in A/A testing. In that case, you will see that the P2BB increases and decreases as you collect more data. The fact that it crossed a threshold (like 95%) at some point during the test is not a guarantee that it would remain above the threshold if you wait until the planned termination time.
Second, it is always risky to stop before observing at least one full time cycle. Version B might be better for visitors at the start of the cycle, but worse for those later in the cycle. If you stop before the end of a full cycle, your results may be biased.
If you want to stop early, think about using stricter criteria for an early stopping point. For example, if you see that the probability becomes extreme (say above 0.999 or below 0.001), you can feel safe in stopping and making a decision. If there really is a difference between A and B, you can still expect to reach those thresholds relatively quickly.
Finally, we also reiterate the importance of waiting for time trends to reveal themselves in your test. You don’t want to decide on the basis of a short time window only to find that the results are very different later in the day or week – suppose weekday visitors respond better to A than B, but that trend flips on the weekend. Making a decision Wednesday from an experiment that began on Tuesday might lead to a bad decision.